

Algorithm
本周选择的算法题是:Find and Replace Pattern。
规则
Given a list of strings words and a string pattern, return a list of words[i] that match pattern. You may return the answer in any order.
A word matches the pattern if there exists a permutation of letters p so that after replacing every letter x in the pattern with p(x), we get the desired word.
Recall that a permutation of letters is a bijection from letters to letters: every letter maps to another letter, and no two letters map to the same letter.
Example 1:
Input: words = ["abc","deq","mee","aqq","dkd","ccc"], pattern = "abb"
Output: ["mee","aqq"]
Explanation: "mee" matches the pattern because there is a permutation {a -> m, b -> e, ...}.
"ccc" does not match the pattern because {a -> c, b -> c, ...} is not a permutation, since a and b map to the same letter.
Example 2:
Input: words = ["a","b","c"], pattern = "a"
Output: ["a","b","c"]
Constraints:
1 <= pattern.length <= 201 <= words.length <= 50words[i].length == pattern.lengthpatternandwords[i]are lowercase English letters.
Solution
use std::{collections::HashMap};
impl Solution {
pub fn find_and_replace_pattern(words: Vec<String>, pattern: String) -> Vec<String> {
let pattern = pattern.as_bytes();
fn is_match(word: &[u8], pattern: &[u8]) -> bool {
let mut map1 = HashMap::<u8, u8>::new();
let mut map2 = HashMap::<u8, u8>::new();
for i in 0..word.len() {
map1.entry(word[i]).or_insert(pattern[i]);
map2.entry(pattern[i]).or_insert(word[i]);
if map1.get(&word[i]).unwrap() != &pattern[i] || map2.get(&pattern[i]).unwrap() != &word[i] {
return false;
}
}
true
}
words.into_iter().filter(|word| is_match(word.as_bytes(), pattern)).collect()
}
}
Review
Zero cost abstractions in Rust
零开销抽象是 C++ 引入的概念:
- What you don’t use, you don’t pay for
- What you do use, you couldn’t hand code any better.
作者在本文中拿 Go 和 Rust 做了对比,解释什么是零开销抽象,总结为两点:
- 相比 Go,Rust 的可执行程序不会包含没有用到的部分 - 无论你在 Go 代码里有没有用到 goroutines,你的可执行程序里总会包含完整的 scheduler 和 runtime,而在 Rust 中只有显式的使用了 Async/Await 才会导致类似的行为
- Trait 没有运行时开销 - Rust 会在编译时为每个 trait impl 生成一份函数版本,在运行时静态分发
我觉得作者的解释不够准确,比如静态调用不符合场景需要时,是可以通过 trait object 实现动态调用的,如果不需要它,则无需为此买单。另一点则是类似 HashSet 的实现,官网中对它的说明是:
A hash set implemented as a
HashMapwhere the value is().
而 () 表示它在内存中不占用任何空间,也就是说 Rust 存在 0 大小的类型,我不需要它,则无需为此买单,同样符合零开销抽象原则。
Tip
数据驱动,也不是唯数据;数据只可以依靠,不可以依赖。
在决策之前,你得先有一些自己逻辑上的分析,然后再基于数据修正认知,最后做出判断。这样做有两个好处,一是可以锻炼你的思考能力,二是可以防止你被数据带偏。
为什么说可能被数据带偏?因为数据只能反映当前的状态,某种程度上,数据是短视的。就像这周我们拒绝了很多不符合团队价值观的广告,从数据上看,收入减少了。这时候团队讨论,是不是应该拒绝那种类型的广告。如果只看数据,很显然,我们不应该拒绝。
但我相信,拉长时间维度看,拒绝伤害用户体验的广告,会让我们挣到更多的钱。有些事,它不可能立即见效,需要我们沉住气,让子弹飞一会儿,而不是浅尝辄止。
抖音电商也有类似的例子,每个商品都有评价,他们会减少对评价较差商品的推荐。如果做 A/B 测试,看交易数据,那短时间内交易量肯定是下降的。但减少对低分商品的推荐这个决策却是对的,它可以提高用户对平台的信任感。不看短期一周的数据,而是看几个月的数据,可以发现交易量的趋势是先下降,然后逐步爬升。
很多时候,短期正确和长期正确是两码事。
数据驱动的前提是建立不偏颇的数据观,一个团队得先理解数据能做什么,不能做什么。这时候,再谈数据驱动才有意义。我见过一些人,他拿着数据,站在数据的制高点上,对别人指手画脚,那一刻,他失去了信仰和思考。
数据是有局限性的。比如独立性、置信度、因果关系、长短期、偶然性等问题。
Share
分享五个好用的 Confluence 宏吧~
A Share Block
Confluence 的 Block 概念和 Notion 的差不多,只不过前者强调的是「同步」,任意页面更新,其他页自动同步,聚合的同时减少了维护成本:

使用方法:
- 用 A Share Block 定义 Block,并为该 Block 设置一个名称
- 其他页面用 Include A Share Block 将该 Block 同步过来
Children Display + Excerpt
这两个宏一起用可以产生相当炸裂的效果,例子:

一次设置,自动同步,适合将多页中的部分内容集中展示出来的场景,比如 change log、迭代 & 发版记录。
使用方法:
- 在子页面中使用 Excerpt 宏
- 用 Children Display 宏展示一组子页面,并将 Excerpt Display 设置为 simple or rich
Help Text
Help 这个名字有点误导人,其实它很有趣:
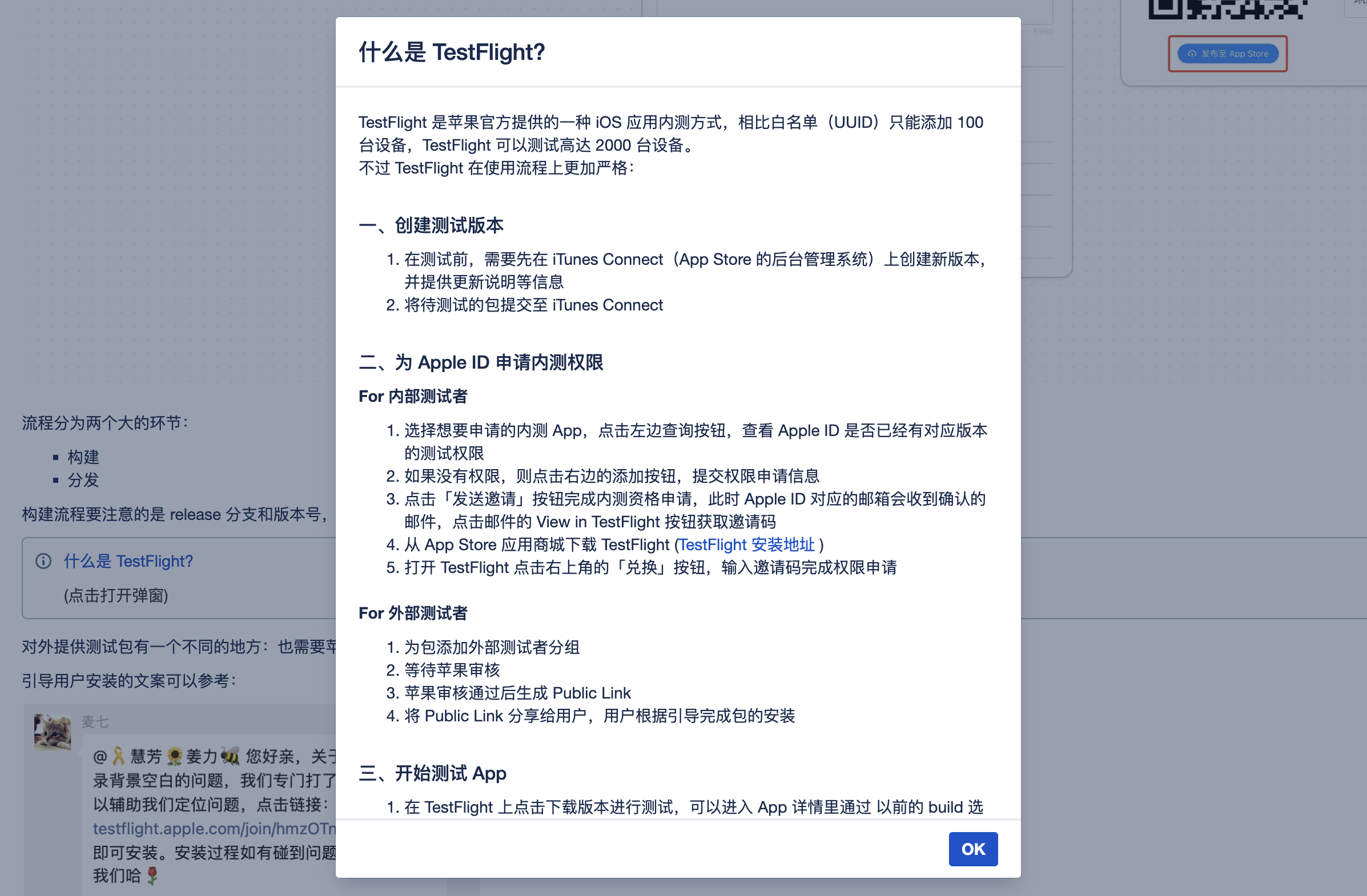
非常适合不希望打开新页面和跳转的场景,而且 Help Text 宏也支持 Include Page、Share Block。
Status
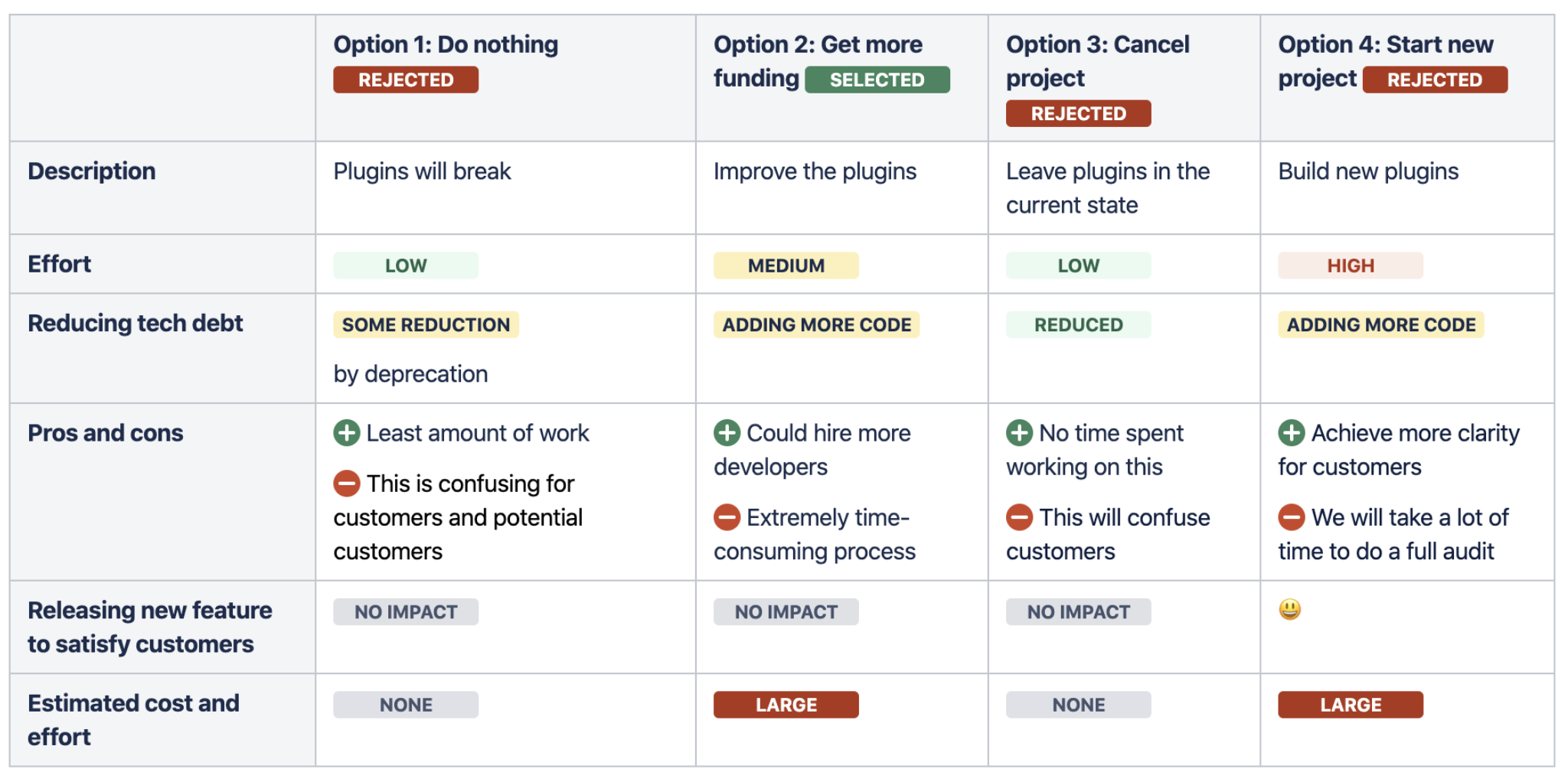
Status 的作用是让内容、醒目、高亮,提升内容可读性,通常结合表格使用,放在某个单元格中,如:

一个更丰富的例子:
Section + Column
虽然 Page layout 预置的 6 种布局很好用,但如果你期望有更强的定制性呢?

通过我们会把内容以 Include Page 的方式填充进来,如果预置布局不适用还得回去修改原布局,而 Section + Column 可以设置更灵活的页面布局,甚至可以在表格单元格中使用,就像这样:

使用方法:
- 先创建一个 Section 宏
- 在 Section 宏内创建多个 Column 宏,为每个 Column 宏指定相对或绝对宽度
最后
常有人拿 Confluence 和飞书文档、语雀等对比,但 Confluence 的定位不是文档服务器,它其实是设计一个网站,你可以用 Livesearch 宏为空间设置一个搜索引擎、为某类标签的内容设置一个搜索引擎,可以用弹窗、Panel、Expand 等各种宏组织你的内容。