


附近的一座小山,山里藏了个小瀑布,适合玩水的季节~
Algorithm
本周选择的算法题是:K-th Smallest in Lexicographical Order。
class Solution:
def findKthNumber(self, n: int, k: int) -> int:
def count_numbers(prefix, n):
count = 0
current = prefix
next_prefix = prefix + 1
while current <= n:
count += min(n - current + 1, next_prefix - current)
current *= 10
next_prefix *= 10
return count
def find_kth_number(k, n):
current = 1
k -= 1
while k > 0:
count = count_numbers(current, n)
if k >= count:
k -= count
current += 1
else:
k -= 1
current *= 10
return current
return find_kth_number(k, n)
Review
Reducing the Size of AI Models
文章探讨了在边缘设备上运行大模型时面临的挑战,并介绍了减小模型大小的多种方法,重点讨论了 Quantization。
以 LLaMA 3.1 为例,8B 参数的版本在 16 位浮点权重内需要 16GB 显存,而 405B 则需要 801GB,因此,训练和运行大型模型需要大量的算力、GPU 显存和能源,而且无法在普通消费级设备上运行推理。
一些常见的减少大小的方法:
LoRA:将高维张量分解为低维张量
- Pruning:通过删除网络中的连接来减少网络大小和复杂性
- Knowledge Distillation:训练一个小型网络来复制大型网络的行为
- Hybrid:结合不同的压缩技术,如 Pruning、quantization 和 Huffman coding
而量化的挑战在于如何在减少表示精度的同时不让模型的准确度掉下来,即在压缩率与准确率损失间做 trade-off。背后的子问题包括:
- 量化的对象是什么,weight?activation?gradient?
- 量化到几位,8 位?4 位?2位?1位?
- 量化参数如何选择,如 step size,clipping value
- 量化参数是否可以自动优化、不同层是否需要不同的量化参数
- …
这篇文章可以作为对 AI 模型量化的一个入门读物,适合对模型优化感兴趣的人阅读。
Tip
git,修改自 BASH_SHA 开始(不包括),所有 commits 的 author,在共享代码空间的场景下较适用:
git rebase -i BASH_SHA -x \
"git commit --amend --author 'xifan <xifan@gaoding.com>' -CHEAD"
Share
Late Chunking: Balancing Precision and Cost in Long Context Retrieval
Late Chunking: Embedding First Chunk Later — Long-Context Retrieval in RAG Applications
什么是 Late Chunking?
Late Chunking 是 JinaAI 于 2024.08.22 发布的用于辅助长上下文检索的新方法,它的优势是:
- 能很好地支持长文档检索:传统的 chuning 在处理长文档时可能会失去重要的上下文信息,导致后续的召回效果不理想,而 Late Chunking 通过对整个文档进行 embedding,由于是基于全局上下文进行的,这样生成的每个 token 就包含了与其他 token 的语义关系,最大化保留了原有的意义。然后再对 embedding 进行分段,有效地解决了上下文信息丢失的问题,提高了检索的精确度
- 对比 ColBERT 的 Late Interaction,更节省资源:利用 Late Interaction 也能减少上下文的精度损失,但它的存储效率很差,存储空间占用通常是 Naive Chunking 的几百倍,与 Late Interaction 相比,Late Chunking 在资源消耗上更为节省,与 Naive Chunking 差不多,但仍能保持较高的检索精度
- 对 Pooling 的应用有别于其他 Chunking:Late Chunking 应用 Pooling 的时机是在对整个文档 embedding 后,将文档级的 embedding 转化为段落级别的 embedding,这对于提高信息检索效率至关重要,而且它还可以根据不同的需求和场景采用不同的 Pooling 方法,比如对 chunk embedding 进行 Mean、Max Pooling,或者 BERT 中的 CLS token
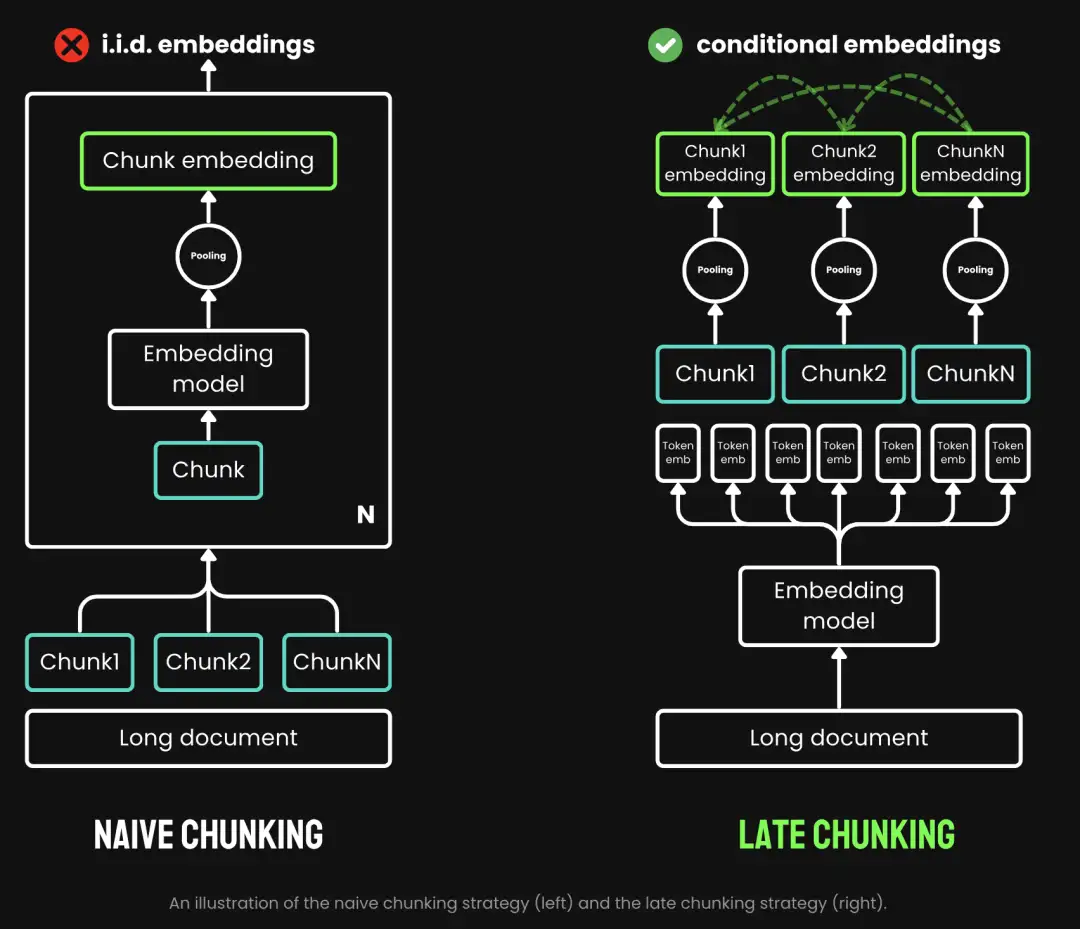
长文档仍然需要大量的 embedding 来表示,但至关重要的是,这些 embedding 都包含了相关的上下文信息。