福建西部连城的冠豸山,每个季节都有不同的美景~
Algorithm
本周选择的算法题是:Find Building Where Alice and Bob Can Meet。
class Solution:
def leftmostBuildingQueries(self, heights: List[int], queries: List[List[int]]) -> List[int]:
n, q = len(heights), len(queries)
ans = [-1] * q
deferred = [[] for _ in range(n)]
pq = []
for i in range(q):
a, b = queries[i]
a, b = min(a, b), max(a, b)
if a == b or heights[a] < heights[b]:
ans[i] = b
else:
deferred[b].append((heights[a], i))
for i in range(n):
for query in deferred[i]:
heapq.heappush(pq, query)
while pq and pq[0][0] < heights[i]:
ans[pq[0][1]] = i
heapq.heappop(pq)
return ans
这是一道有趣的题目,很容易在时间和空间上达不到要求~
Review
CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion
介绍了一个称为 CacheBlend 的系统,它通过优化 KV Cache 加速了 LLM 的推理。
对比 Prefix Caching 和 Full KV reuse:
- Prefix Caching 的问题在于无法复用非前缀 chunks 的 KV Cache
- Full KV reuse 的问题在于忽略了 cross-attention
Prefix Caching 和 Full KV re-compute 准确性高,但计算慢;Full KV reuse 虽然快,但在特定场景下会输出错误的内容:
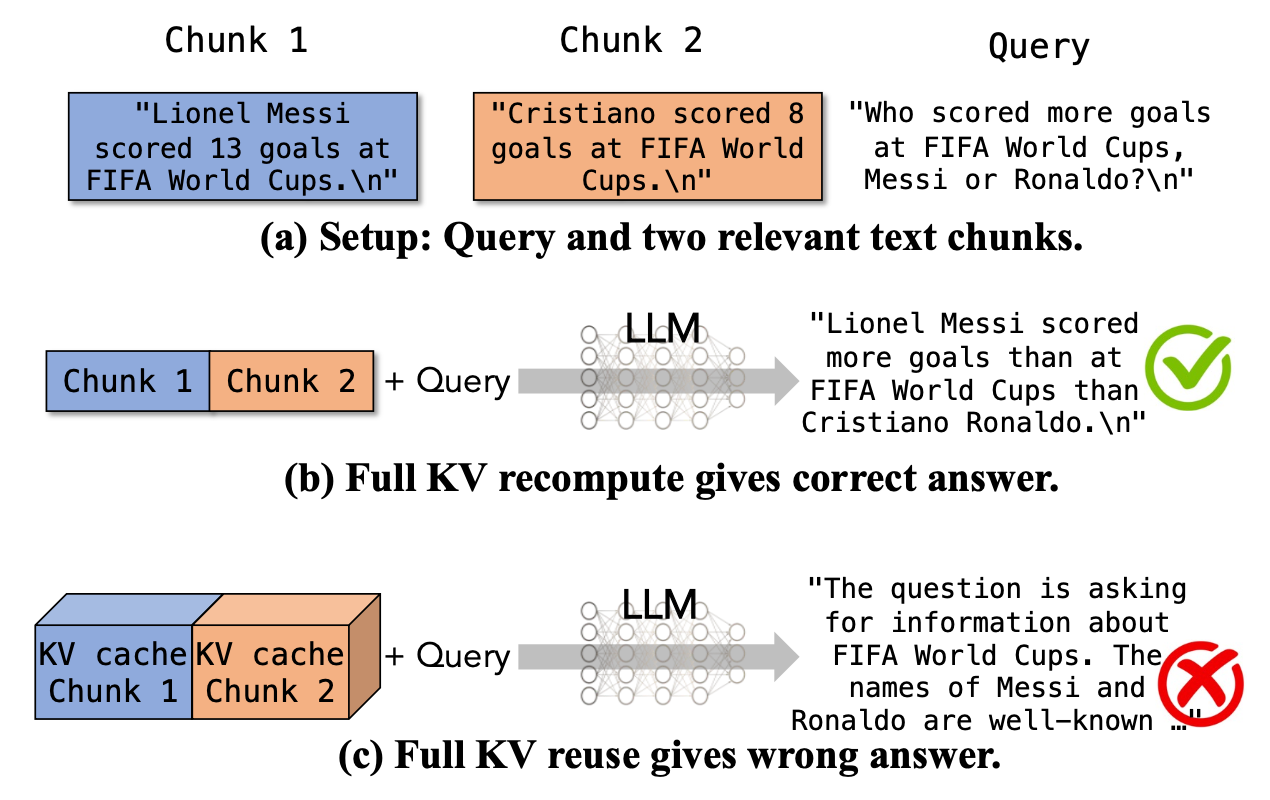
CacheBlend 的目标是又快又准确,它允许 pre-computed KV Cache 被复用,并有选择性的重新计算一小部分 KV,以此达到和 Full KV re-compute 相同的生成质量。
CacheBlend 最复杂的地方大概就是选择更新哪一部分了:
- 由于注意力矩阵的稀疏性,大多数 tokens 的注意力值相对较低,只有一小部分 tokens 的 KV 值需要更新以保持生成质量,按作者的经验,每层不到 15% 的更新比例即可达到质量目标
- 利用 ROPE 计算出 pre-computed KV Cache
- 只更新 KV 偏差最大的部分。假设上一层 KV 偏差大的 token 大概率也是下一层 KV 偏差大的,那么只需要全量计算第一层的 tokens,将得到的第二层 KV Cache 和第二层的 pre-computed KV Cache 对比,从中筛选出 KV 偏差最大的部分,然后只计算这部分,之后类似,每一层只计算上一层的子集
此外,CacheBlend 会根据存储设备的性能来智能选择重新计算的比例,以确保计算的延迟接近数据加载的延迟。也就是说当存储设备性能很好时,即使选择更高的计算比例(超过 15%),额外的 KV 重计算延迟也可以被存储设备的快速加载速度所掩盖,从而不会增加额外的推理延迟(TTFT)。
这套系统目前只在 vLLM 中实现,还是有较高的复杂度。
Tip
Ling,一个能够流式处理 LLM 生成内容的框架。
Share
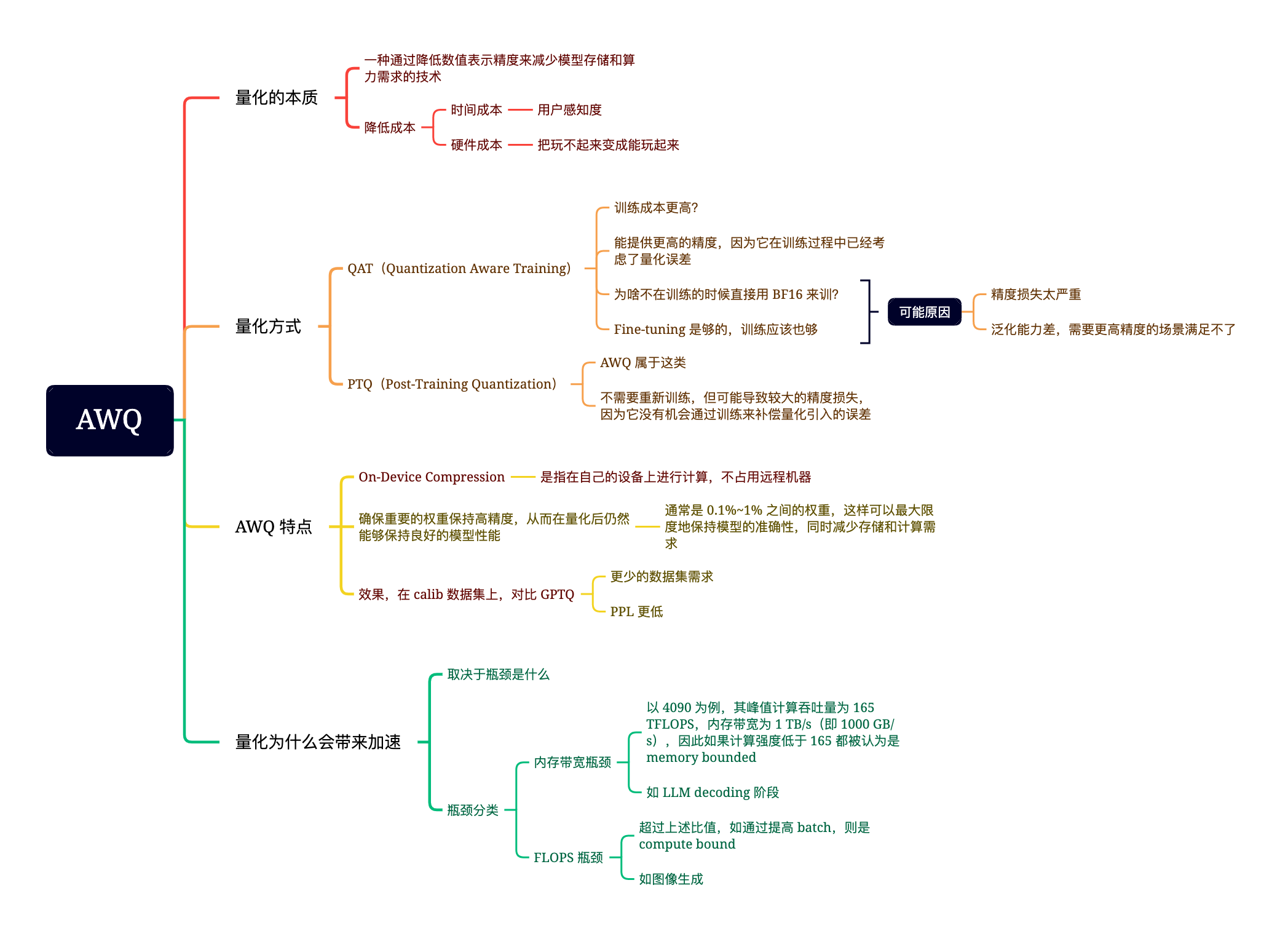
AWQ 论文记录: