


一次绝佳的啤酒之旅,第一次感受直接从发酵罐里打精酿啤酒的味道~
Algorithm
本周选择的算法题是:Shifting Letters II。
class Solution:
def shiftingLetters(self, s: str, shifts: List[List[int]]) -> str:
n = len(s)
changes = [0] * (n + 1)
for start, end, direction in shifts:
delta = 1 if direction else -1
changes[start] += delta
changes[end + 1] -= delta
curr_shift = 0
result = []
for i, char in enumerate(s):
curr_shift = (curr_shift + changes[i]) % 26
new_char = chr((ord(char) - ord('a') + curr_shift) % 26 + ord('a'))
result.append(new_char)
return ''.join(result)
在处理大量区间更新操作时,差分数组特别有用。当我们后续计算前缀和时:
- [start, end] 范围内的所有位置都会受到 delta 的影响
- end + 1 之后的位置会被抵消,保持不变
这样就实现了区间更新的效果。
Review
“Give Me BF16 or Give Me Death”? Accuracy-Performance Trade-Offs in LLM Quantization
这篇论文来自 Neural Magic 和奥地利科学技术研究所,主要研究了 LLM 量化在推理加速中的准确性与性能之间的权衡。
实验结果:
- 准确性
- W8A8-FP 量化:在所有模型规模上几乎是无损的,平均准确度与未量化模型相当或在评估误差范围内
- W8A8-INT 量化:在适当调整后,准确度损失仅为 1-3%
- W4A16-INT 量化:在准确性上与8位整数量化具有竞争力
- 性能
- W4A16-INT:在同步部署中表现最佳,对于中等规模 GPU 上的异步部署也是首选
- W8A8 格式:在高端 GPU 上的中等和大型模型的异步 “Continuous batching” 部署中表现优异
这些发现为模型部署时提供了指导,并为 researcher 在方法改进方面提供了动力。
Tip
老牌的目录导航工具 autojump 不怎么更新了,后起之秀 zoxide 今年也在 star 数上超过了 autojump,受到了社区的追捧:
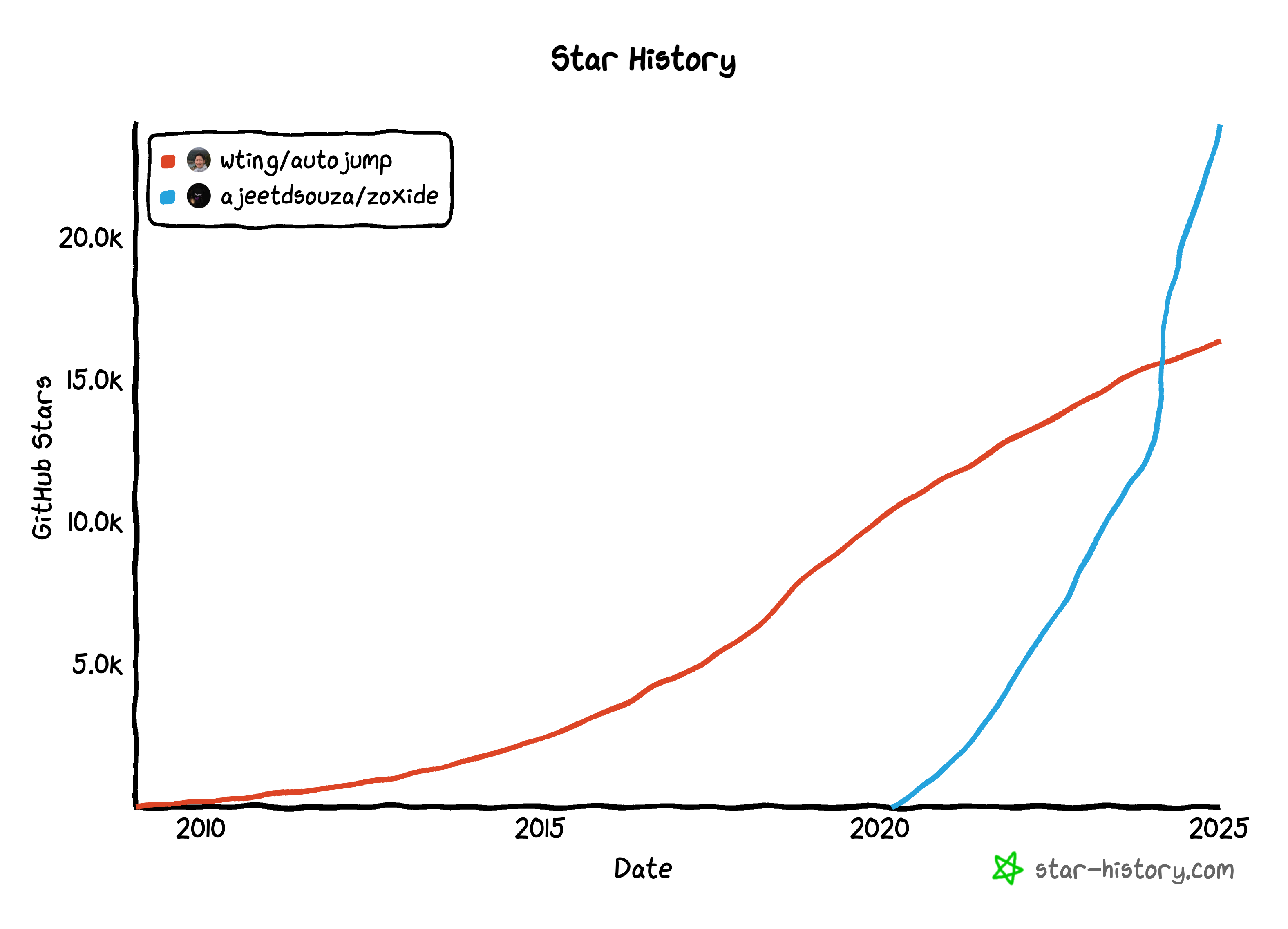
它们在功能上差异不大,都是用于提高命令行目录导航效率的工具,但在实际和设计上有些区别:
- autojump 基于 python,zoxide 基于 rust,后者的性能和响应速度更快
- zoxide 能自动清理数据库
- zoxide 的跨平台支持更好
zoxide 的算法描述参见:Algorithm。
如果你原本是 autojump 的用户,已经习惯了 j 命令,那么在 ~/.zshrc 文件里配置 zoxide 时只需要:
eval "$(zoxide init zsh --cmd j)"
Share
MoE
MoE(Mixture of Experts,混合专家模型)是一种深度学习架构,旨在提升模型的性能和计算效率,其核心思想是通过引入多个独立的专家模型(Experts),并在处理输入时动态选择激活其中的一部分,从而减少计算量并提高训练和推理速度。
以 Mixtral-8x7B-32K MoE 模型为例,它由 32 个相同的 MoE Transformer Block 组成,MoE Transformer Block 与普通的 Transformer Block 的最大差别在于其 FFN 层替换为了 MoE FFN 层,tensor 首先会经过一个 Gate Layer 计算每个 Expert 的得分,并根据得分从 8 个 Expert 中挑出 Top-K 个 Experts,将 tensor 经过这 Top-K 个 Experts 的输出后聚合起来,从而得到 MoE FFN 层的最终输出:
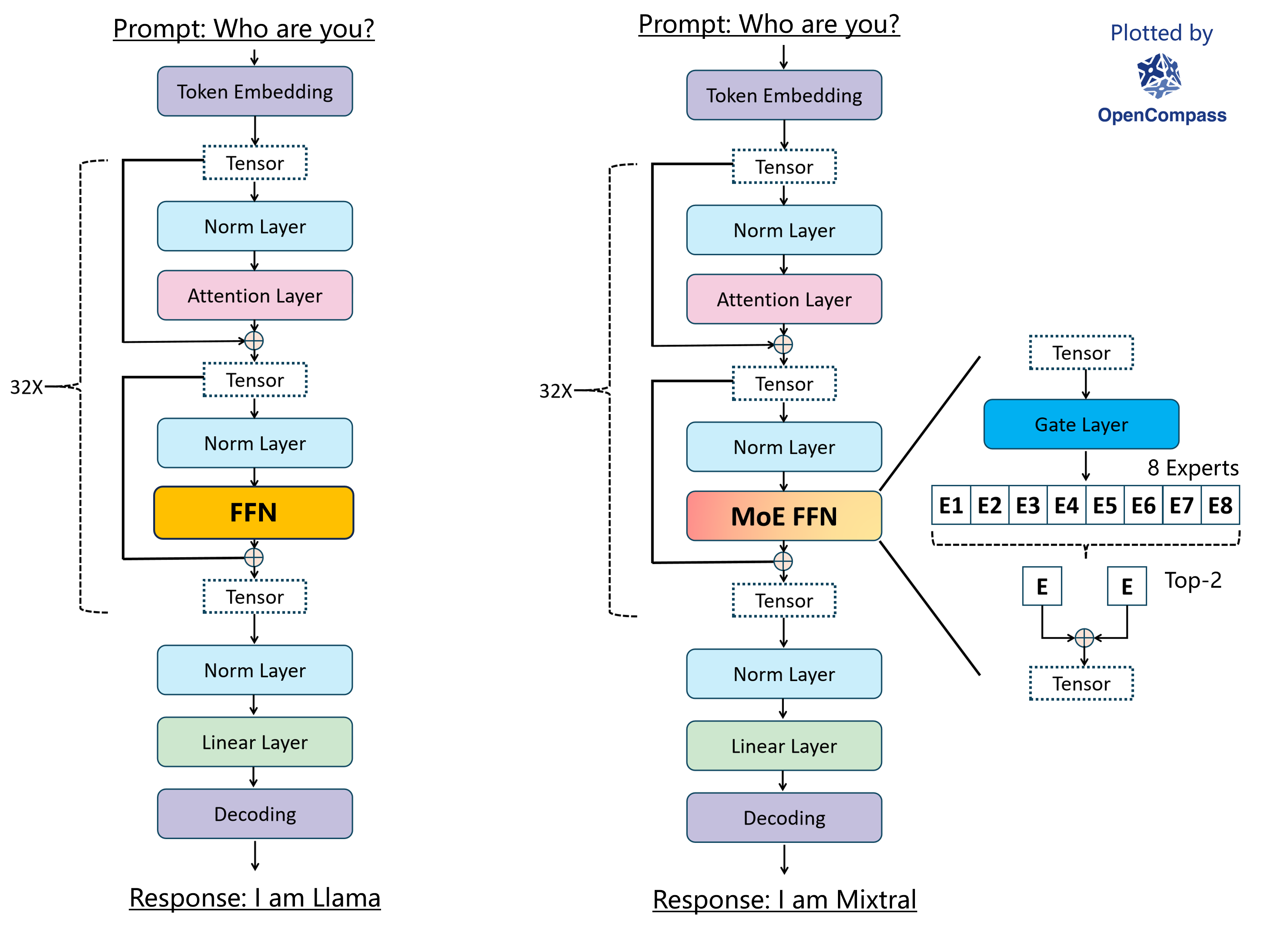
https://github.com/open-compass/MixtralKit
MoE 架构有两个重要组成部分:
- 门控网络(Gating Network)
- 定义:负责决定哪些专家模型将被激活来处理特定输入的机制
- 功能:输出一个概率分布,指示每个专家被选中的概率,从而实现动态路由
- 专家模型(Experts)
- 定义:一组独立的神经网络,每个专家专注于处理特定类型的数据或任务
- 功能:通过专业化分工,提升对复杂任务的处理能力
MoE 模型虽然总参数量大,但通过门控网络引入了稀疏性后,在实际运行时参与计算的参数量相对较少,允许模型仅对特定部分执行计算,从而提高计算效率和模型性能,但是一个关键的挑战是如何平衡各个专家之间的计算负载,如果某些专家负载过高,而另一些专家闲置,就会导致资源浪费和性能下降。门控网络为了确保每个专家均匀分配 token,引入了辅助损失函数以解决负载平衡问题。
顺带一提,最近很火的 DeepSeek V3 在这方面提出了一个非常巧妙的解决方案 — 无辅助损失的负载均衡策略:
- 传统的 MoE 模型通常使用辅助损失函数来鼓励各个专家之间的负载均衡,但 DeepSeek V3 无需额外的辅助损失函数,而是通过巧妙地设计路由机制和门控值的计算方式,让模型在训练过程中能够自发地实现负载均衡
- DeepSeek V3 通过专家亲和度 (token-to-expert affinity) 机制来实现隐式负载均衡,每个 token 会根据其内容与各个专家的亲和度来动态选择激活的专家。通过这种方式,模型自然地会将不同类型的 token 分配给最合适的专家
- 模型倾向于选择那些能够最大化其性能的专家,从而在训练过程中自动实现负载均衡
- 专家专业化,使得不同的专家倾向于处理不同领域或类型的输入,从而提高了模型的整体性能
- 为了防止极端不平衡,DeepSeek V3 也加入了一个互补的序列级平衡损失,但其贡献很小,主要机制仍是无辅助损失的负载均衡策略
虽然 MoE 在训练成本和性能上有很大优势,但其训练难度较高,主要体现在以下几个方面:
- 专家负载均衡问题带来的动态路由机制复杂性:MoE 模型通过门控网络动态选择合适的专家来处理输入数据,这种动态路由机制增加了模型的复杂性,门控网络需要学习如何高效地分配任务给不同的专家,这不仅增加了训练的难度,还可能导致训练过程中的不稳定性和收敛问题
- 高内存需求与通信开销:尽管 MoE 可以减少计算需求,但仍需将所有参数加载到内存中,这对内存要求较高,而且随着模型规模的增加,训练期间的高效通信变得越来越重要,专家之间的数据交换和并行训练需要频繁的通信,这增加了通信成本和延迟
- 模型复杂性和过拟合风险:随着专家数量的增加,MoE 模型的复杂性也会增加,相较于稠密模型更容易产生过拟合,尤其是在小规模任务上表现不佳,微调过程中也面临泛化困难的问题
- 复杂的超参数选择:MoE 模型的训练策略需要精细设计,包括参数初始化、学习率调度和数据配比等,选择适当的超参数以达到最佳性能是一个复杂的任务,每个因素都会对最终模型的性能产生重要影响
尽管如此,MoE 模型的发展前景广阔,GPT-4 据称采用了 16 个 Experts,Qwen 也证明了 MoE 在大规模语言模型中的有效性,DeepSeek V3 采用了无辅助损失的负载均衡策略,进一步优化了 MoE 架构的性能和训练效率。