

Algorithm
本周选择的算法题是:Combination Sum II
规则如下:
Given a collection of candidate numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target.
Each number in candidates may only be used once in the combination.
Note:
- All numbers (including
target) will be positive integers. - The solution set must not contain duplicate combinations.
Example 1:
Input: candidates = [10,1,2,7,6,1,5], target = 8,
A solution set is:
[
[1, 7],
[1, 2, 5],
[2, 6],
[1, 1, 6]
]
Example 2:
Input: candidates = [2,5,2,1,2], target = 5,
A solution set is:
[
[1,2,2],
[5]
]
Solution
我实现的方案:
Runtime:36 ms,快过 97.99%。
Memory:12.7 MB,低于 100%。
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
candidates.sort()
result = []
self.recursive(0, candidates, target, result, [])
return result
def recursive(self, start: int, candidates: List[int], target: int, result: List[List[int]], path: List[int]):
if target == 0:
result += [path]
return
for index in range(start, len(candidates)):
candidate = candidates[index]
if index > start and candidate == candidates[index - 1]:
continue
if candidate > target:
return
self.recursive(index + 1, candidates, target - candidate, result, path + [candidate])
参考了评论区的做法。
Review
Basic Performance Optimization in Django
“如果你无法衡量它,那么也无法改善它。“
– Lord Kelvin
作者分享了一些 Django 性能优化的技巧,常见的技巧略过,因为 Django 的文档已经很全面了,我从该文中发现了几个我不曾用过的:
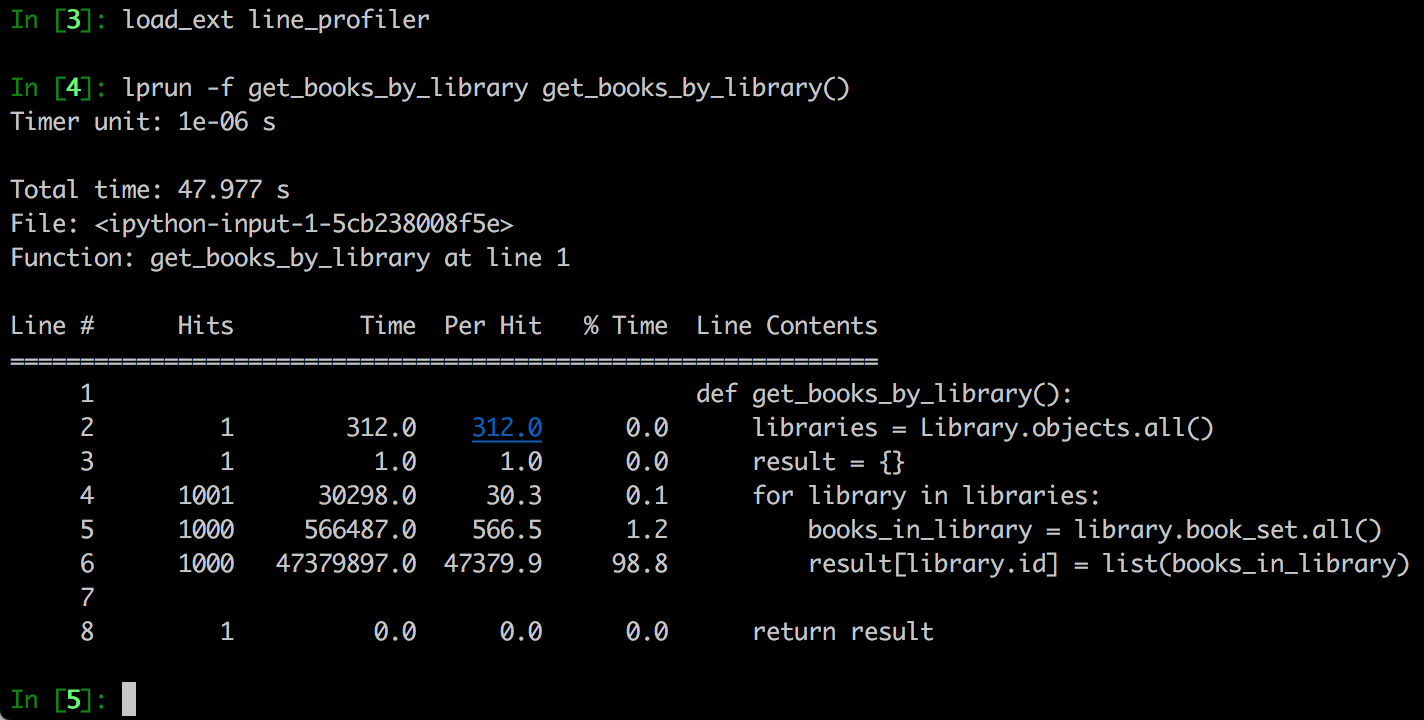
line_profiler
一个 Python 库,需要通过 pip 安装,使用方式:
def books_by_library_id_view(request):
from IPython import embed; embed()
books_by_library_id = get_books_by_library_id()
...
return HttpResponse(response)
生成结果:
SQL Logging
只需配置一下就能打印每一条 SQL 语句执行的日志:
# settings.py
LOGGING = {
'version': 1,
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
}
},
'handlers': {
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
}
},
'loggers': {
'django.db.backends': {
'level': 'DEBUG',
'handlers': ['console'],
}
}
}
timeit
Python 内置的模块:
In [12]: timeit(get_books_by_library_id, number=10)
Out[12]: 6.598360636999132
In [13]: timeit(get_books_by_library_id_one_query, number=10)
Out[13]: 0.677092163998168
Tip
这是一个好工具,让我帮你百度一下:)
Share
降级设计
降级设计的目的:解决资源不足和访问量过大的问题。
降级的 trade-off:
- 降低一致性 - 从强一致性变成最终一致性
- 停止次要功能 - 停止访问不重要的功能,从而释放出更多的资源
- 简化功能 - 把一些功能简化掉,简化业务流程,或者只返回部分数据
降级设计的重点:
- 梳理业务功能,哪些是 must-have,哪些是 nice-to-have
- 需要牺牲一致性,读操作可以考虑缓存来解决,写操作需要异步调用,需要有完整的日志记录
- 提供一个系统的配置开关
- 数据降级需要前端配合
- 数据传输需要有一个字段区分当前是否在降级中
弹力设计总结
为了向用户承诺 SLA,服务不能是单体的,需要在架构中冗余服务,需要用到的技术:
- 负载均衡 + 服务健康检查 - 可以使用像 Nginx 或 HAProxy 这样的技术
- 服务发现 + 动态路由 + 服务健康检查 - 比如 Consul 或 ZooKeeper
- 自动化运维 - Kubernetes 服务调度、伸缩和故障迁移
接着是服务隔离,需要对服务进行拆分和解耦:
- bulkheads 模式 - 业务分片、用户分片、数据库分片
- 自包含系统 - 单体应用到微服务的中间状态,把一组密切相关的微服务给拆分出来,没有外部依赖即可
- 异步通讯 - 服务发现、事件驱动、消息队列、业务工作流
- 自动化运维 - 需要一个服务调用链和性能监控的监控系统
接着是容错设计:
- 错误处理 - 调用重试 + 熔断 + 服务幂等性设计
- 一致性 - 强一致性使用两阶段提交、最终一致性采用异步通讯
- 流控 - 使用限流 + 降级
- 自动化运维 - 网关流量调度,服务监控
分布式锁
分布式系统下需要有一个分布式锁,这个锁的特点是:
- 安全性 - 任意时刻具有排他性
- 避免死锁 - 客户端最终一定可以获取到锁
- 容错性 - 只要锁服务的大部分节点存活,客户端就可以执行加解锁操作
常见的锁服务设计:
- 需要一个过期时间
- 客户端获取锁时需要生成一个唯一值
- 客户端需要获取、比较数据的版本号
- 使用数据库作为锁服务
锁服务设计的重点:
- 锁还不回来怎么办?需要有锁一定被释放的方式
- 如果出现了两个进程拿到了同一个锁:
- 用 CAS(Compare And Swap)保证不出问题
- 用数据库的乐观锁保证不出问题
- 高可用
- 提供非阻塞方式的锁服务
- 考虑锁的可重入性
配置中心
动态配置的区分维度:
- 按运行环境分 - 开发、测试、预发、生产等
- 按依赖分 - 内部配置和外部配置,如 MySQL 的连接配置
- 按层次分 - 基础层、中间平台层、应用层等
配置中心的设计重点:
- 配置项应该由专人(运维或者架构师)维护:
- key 应该有命名规范,有名字空间
- value 应该是选项
- 外部配置放在服务发现系统中
- 需要考虑不同的运行环境下使用不同的配置,如开发环境和测试环境
- 需要有一个整体的版本管理,最好能与软件的版本号关联
- 需要有一个配置管理工具,可能是命令行的,也可以是 web 的
- 配置更新要作为一个事务处理
- 需要有一个配置更新的控制器
边车模式
边车模式的核心作用:控制和逻辑分离,从而提高系统整体的稳定性和可用性。
对于标准化的组件和模块,一般有两种设计方式:
- 通过 SDK、Lib 或 Framework - 与应用密切集成,有利于资源的利用和应用的性能,但是对应用有侵入性,容易受应用的编程语言和技术限制;需要与应用同步更新与编译
- Sidecar(边车模式) - 对应用没有侵入性,并且不受应用语言和技术的限制;但是 RPC 增加了应用的延迟与服务的依赖性,大大增加管理、托管、部署的复杂度
Sidecar 设计重点:
- 进程间采用网络调用的方式来通信
- 两层服务协议 - 对内贴近本地服务;对外尽量开发、标准化
- 不要把业务逻辑设计放到 Sidecar 中
- 考虑上下文的传递,如 HTTP 请求头
Sidecar 适用的场景:
- 老应用的改造
- 对对语言的分布式服务系统进行管理和扩展
- 应用服务由不同的供应商提供
Sidecar 不适用的场景:
- 架构并不复杂的时候,API Gateway 或者 Nginx 和 HAProxy 就能搞定
- 服务间的协议不标准且无法转换
- 不需要分布式架构
服务网格
什么是 Service Mesh:专注于处理服务和服务间的通讯,负责构造一个稳定可靠的服务通讯基础设施,并让整个架构更为先进和 Cloud Native:
- 一个基础设施
- 一个轻量的服务通讯的网络代理
- 对于应用服务来说是无侵入的
- 用于解耦和分离分布式系统架构中控制层面上的东西
设计重点:
- Service Mesh 需要调度流量,可能导致服务的异常运行
- Service Mesh 一定要是高可靠或者出现了故障有 workround 的方式:
- 可以为集群部署一个集中式的 Sidecar,为本机的 Sidecar 兜底
- 作为基础设施独立部署,需要和 K18S 密切结合
网关模式
网关需要的功能:
- 请求路由 - 调用端不需要知道自己需要用到的其他服务的地方,全部统一地交给 Gateway 来处理
- 服务注册 - 后端的服务实例可以把其提供服务的地址注册、取消注册,对 restful 来说,注册是针对 URI、method、HTTP 头
- 负载均衡 - 网关需要在各个对等的服务实例上做负载均衡策略
- 弹力设计 - 网关可以集成弹力设计中的那些异步、重试、幂等、流控、熔断、监控等,让应用服务只关心自己的业务逻辑(数据面)而不是控制逻辑(控制面)
- 安全方面 - SSL 加密及证书管理、Session 验证、授权、数据校验,以及对请求源进行恶意攻击的防范
网关还可以做一些有趣的事:
- 灰度发布 - 可以对相同服务不同版本的实例进行导游,还可以收集相关的数据,对软件质量的提升和产品试错都有非常积极的意义
- API 聚合 - 可以帮助用户端将多个单独请求聚合成一个请求
- API 编排
和网关相似的设计模式:
- Sidecar - 主要用来改造已有的服务,避免“政治复杂度”太高的问题
- Service Mesh - Sidecar 越来越多,需要统一管理的控制器,在这个控制器中,将非业务功能的东西全部实现在 Sidecar 和 Controller 中,形成一个网格,业务方只需要把服务放进这个网格即可
- Gateway - Service Mesh 的架构和部署太过于复杂,可以将 Sidecar 的粒度变为可粗可细
网关设计的重点:
- 高性能
- 高可用
- 集群化 - 组成一个集群,并可以自己同步集群数据,而不依赖第三方系统
- 服务化 - 不间断的情况下修改配置
- 持续化 - 需要重启时,新的请求被分配到新的进程中,老的进程处理完后退出
- 高扩展 - 由于需要承接流量和请求,或多或少会有一些业务上的东西,一个好的 Gateway 应该是可扩展和能二次开发的,像 Serverless 和 FaaS 那样
运维方面的设计原则:
- 业务松耦合,协议紧耦合
- 应用监控,提供分析数据
- 用弹力设计保护后端系统
- DevOps
架构方面的设计原则:
- 不要直接在网关的代码里内置聚合后端服务的功能,考虑做成插件或形成 Serverless 服务
- 网关应该靠近后端服务,并和后端服务在同一个内网中
- 需要成为一个集群来分担前端的流量
- 对于服务发现可以做一个时间不长的缓存,避免每次请求都去查一个相关服务的地址
- 为网关考虑 bulkhead 设计,用不同的网关服务不同的后端服务
安全方面的考虑:
- 加密数据
- 校验用户请求
- 检测异常访问