

Algorithm
本周选择的算法题是:Champagne Tower
规则如下:
We stack glasses in a pyramid, where the first row has 1 glass, the second row has 2 glasses, and so on until the 100th row. Each glass holds one cup (250ml) of champagne.
Then, some champagne is poured in the first glass at the top. When the top most glass is full, any excess liquid poured will fall equally to the glass immediately to the left and right of it. When those glasses become full, any excess champagne will fall equally to the left and right of those glasses, and so on. (A glass at the bottom row has it’s excess champagne fall on the floor.)
For example, after one cup of champagne is poured, the top most glass is full. After two cups of champagne are poured, the two glasses on the second row are half full. After three cups of champagne are poured, those two cups become full - there are 3 full glasses total now. After four cups of champagne are poured, the third row has the middle glass half full, and the two outside glasses are a quarter full, as pictured below.
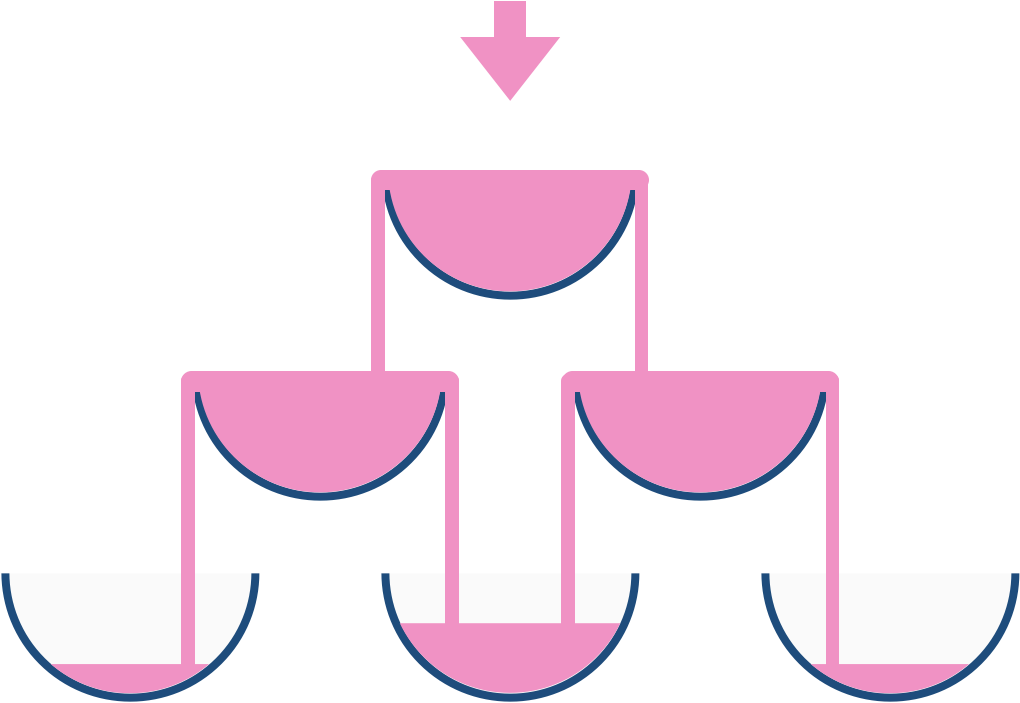
Now after pouring some non-negative integer cups of champagne, return how full the j-th glass in the i-th row is (both i and j are 0 indexed.)
Example 1:
Input: poured = 1, query_glass = 1, query_row = 1
Output: 0.0
Explanation: We poured 1 cup of champange to the top glass of the tower (which is indexed as (0, 0)). There will be no excess liquid so all the glasses under the top glass will remain empty.
Example 2:
Input: poured = 2, query_glass = 1, query_row = 1
Output: 0.5
Explanation: We poured 2 cups of champange to the top glass of the tower (which is indexed as (0, 0)). There is one cup of excess liquid. The glass indexed as (1, 0) and the glass indexed as (1, 1) will share the excess liquid equally, and each will get half cup of champange.
Note:
pouredwill be in the range of[0, 10 ^ 9].query_glassandquery_rowwill be in the range of[0, 99].
Solution
class Solution:
def champagneTower(self, poured: int, query_row: int, query_glass: int) -> float:
flow_table = [[0] * x for x in range(1, query_row + 2)]
flow_table[0][0] = poured
for i in range(query_row):
for j in range(i + 1):
remain = (flow_table[i][j] - 1) / 2
if remain > 0:
flow_table[i+1][j] += remain
flow_table[i+1][j+1] += remain
return min(1, flow_table[query_row][query_glass])
利用一张路径表,将每一行时的剩余香槟量记下,并以此更新下一行的香槟量。
Review
Understanding async-await in Javascript
async 函数是由 event loop 异步控制的,使用一个隐式的 promise 返回结果。语法和代码结构更像标准的异步函数。
总结一下:
async函数会隐式地返回一个promise对象- 使用
async-await模式的时候要记得用try-catch处理错误 - 当在循环或迭代器里使用
await时要注意,你的每一次循环可能是不相关的,这种情况下应该用并行的方式 await只面向单个promise,如果你想并行执行,可以用Promise.all函数- 一旦
promise对象创建完,它就开始执行了,与什么时候用then或者await无关 await只确保仅当resolve完成后,才会执行下一行代码
Tip
本周学习到的一些内容:
写幂等 Bash 脚本的方法:
新建文件,
touch example.txt,**touch ** 命令本身就是幂等的,重复调用只会更新文件的修改日期新建目录,
mkdir -p dir,-p flag 将确保目录存在时调用不会报错新建一个 symbolic,
ln -sf source target,-f flag 将确保 target 存在时不会报错删除文件,
rm -f example.txt,-f flag 将忽略不存在的文件修改文件,得加上一些判断条件了,比如:
if ! grep -qF "/mnt/dev" /etc/fstab; then echo "/dev/sda1 /mnt/dev ext4 defaults 0 0" | sudo tee -a /etc/fstab fi当 fstab 中不存在 “/mnt/dev” 时才写入。grep 中的 q flag 表示静默模式,F flag 的效果同 fgrep 一样,将 pattern 解释为固定的字符串
检查变量、文件或目录是否存在:
[ -z "" ] && echo "Empty" || echo "Not Empty" # 检测空字符串 [ -f "/etc/conf/foo.txt" ] && echo "Exists" || echo "Not Exists" # 检测文件是否存在 ... -d # 用于判断目录是否存在,完整的测试指令见 man test ...格式化磁盘,这里用到了 Linux 下的 blkid:
blkid "$VOLUME_NAME" || mkfs.ext4 "$VOLUME_NAME" # 获取磁盘 UUID 信息时才格式化Mac 下貌似得借助
diskutil命令装载磁盘
if ! mountpoint -q "$DATA_DIR"; then # -q,静默模式 mount -o discard,defaults,noatime "$VOLUME_NAME" "$DATA_DIR" fi
写幂等脚本在分布式系统或 At-Least-Once queues 中尤其重要,大多数情况下,我们不需要强一致性,只需要做到最终一致性就行了,这就要求我们的脚本是可以执行多次而没有副作用。
JavaScript 手动触发
change事件:// 创建事件 const event = document.createEvent("HTMLEvents"); event.initEvent('change', false, true); // 触发 checkbox.dispatchEvent(event);
Share
本周分享:
Read Time and You
大约需要2分钟的时间阅读 :)
最近看了这篇老文后,不经意的思考起产品需求背后的逻辑。现在绝大多数的内容平台普遍有一个估算阅读时长的功能,这个功能看起来太自然了,仿佛就应该在那,但是它的历史并不长,出现后迅速地普及开了,我们花了多久才“发明”它?
好产品背后的逻辑和程序员修复 Bugs 的速度是一样的,人们总能迅速解决实际影响到自己的问题,其他问题反正没有影响到自己使用,那就优先级低一点吧。
在面对阅读时长这个问题时,我以往的解决方案是:1. 快速滚动到底部,判断下阅读要多久;2. 随便滚动一下,看一眼滚动条,判断下阅读要多久。很明显没什么新意,而且效率很低,如果发现问题的人有更好解决问题的办法,又恰好能决策一款产品,那就太幸运了,这个问题有解了。
角色不同看问题的角度也不同,从用户的角度来看,一个好的产品它应该:
- 源于真实世界
- 能解决具体问题
从企业角度来看,嗯,这就太复杂了。
ps:Medium 目前是建议 265 WPM,中日韩是 500 WPM。