

Algorithm
本周选择的算法题是:Print Binary Tree
规则如下:
Print a binary tree in an m*n 2D string array following these rules:
- The row number
mshould be equal to the height of the given binary tree. - The column number
nshould always be an odd number. - The root node’s value (in string format) should be put in the exactly middle of the first row it can be put. The column and the row where the root node belongs will separate the rest space into two parts (left-bottom part and right-bottom part). You should print the left subtree in the left-bottom part and print the right subtree in the right-bottom part. The left-bottom part and the right-bottom part should have the same size. Even if one subtree is none while the other is not, you don’t need to print anything for the none subtree but still need to leave the space as large as that for the other subtree. However, if two subtrees are none, then you don’t need to leave space for both of them.
- Each unused space should contain an empty string
"".`` - Print the subtrees following the same rules.
Example 1:
Input:
1
/
2
Output:
[["", "1", ""],
["2", "", ""]]
Example 2:
Input:
1
/ \
2 3
\
4
Output:
[["", "", "", "1", "", "", ""],
["", "2", "", "", "", "3", ""],
["", "", "4", "", "", "", ""]]
Example 3:
Input:
1
/ \
2 5
/
3
/
4
Output:
[["", "", "", "", "", "", "", "1", "", "", "", "", "", "", ""]
["", "", "", "2", "", "", "", "", "", "", "", "5", "", "", ""]
["", "3", "", "", "", "", "", "", "", "", "", "", "", "", ""]
["4", "", "", "", "", "", "", "", "", "", "", "", "", "", ""]]
Note: The height of binary tree is in the range of [1, 10].
Solution
我实现的方案:
Runtime:44 ms,快过 53.21%。
Memory:13.1 MB,低于 80.41%。
class Solution:
def printTree(self, root: TreeNode) -> List[List[str]]:
def level_traversal(root: TreeNode) -> (int, int):
m, stack = 0, [root]
while stack:
count = len(stack)
m += 1
while count > 0:
node = stack.pop(0)
if node.left:
stack.append(node.left)
if node.right:
stack.append(node.right)
count -= 1
return m, (1 << m) - 1
m, n = level_traversal(root)
matrix = [[""] * n for x in range(m)]
level, stack = 0, [(root, n, -1)]
while stack:
count = len(stack)
while count > 0:
node, parent_location, assign = stack.pop(0)
node_location = parent_location + (1 << (m - level - 1)) * assign
matrix[level][node_location] = str(node.val)
if node.left:
stack.append((node.left, node_location, -1))
if node.right:
stack.append((node.right, node_location, 1))
count -= 1
level += 1
return matrix
先用一个层序遍历找出树的高度,然后构建一个矩阵进行填充;两个操作都是用栈而不是递归完成的,代码看起来会多一些。
Review
Protocol Buffers: Avoid these uses
作者认为 Protobuf 有如下问题:
- Protos make bad complex objects
- Losing logical objects
- Protos make a bad configuration language
至于这些问题在实际使用中会影响哪些场景就见人见智了。
在我看来前两个问题很类似,关键是看你怎么定义 Protobuf 的,如果只是将它作为一个 DTO 那并不会有什么问题,因为在它之上你会有自己的业务模型,也就是作者提到的 native type,这样仅仅是让 Protobuf 能发挥出自己的优势即可。
第三个问题是一个 trade-off,因为 Protobuf 是一个二进制格式,优点是序列化效率高,占用空间小,但是相对于 XML、JSON、Yaml、Toml 来说,它不具备自解释性,必须通过 .proto 文件来读。老实讲,这个“缺点”并不妨碍它的流行。
在另外一篇极端的文章 Protobuffers Are Wrong 有提到 Protobuf 的一些设计的问题,其中作者置疑了官方宣称的前向、后向兼容性,观点是:
What protobuffers are is permissive. They manage to not shit the bed when receiving messages from the past or from the future because they make absolutely no promises about what your data will look like. Everything is optional! But if you need it anyway, protobuffers will happily cook up and serve you something that typechecks, regardless of whether or not it’s meaningful.
This means that protobuffers achieve their promised time-traveling compatibility guarantees by silently doing the wrong thing by default. Of course, the cautious programmer can (and should) write code that performs sanity checks on received protobuffers. But if at every use-site you need to write defensive checks ensuring your data is sane, maybe that just means your deserialization step was too permissive. All you’ve managed to do is decentralize sanity-checking logic from a well-defined boundary and push the responsibility of doing it throughout your entire codebase.
对于新增的属性会采用非常宽松的方式来执行反序列化,哪怕你标记它为 required(ps: proto3 不再需要用户指定 required、optional 这些关键字)。
虽然有人不喜欢 Protobuf,它也可能不适合每一种场景,不过它的优点还是很明显的:
- 序列化效率高,速度快
- 占用空间小
- 对二进制支持更好,JSON 序列化需要先将二进制转换成字符串
- 安全性更好(Google 的亲儿子),近年来流行的 JSON 框架曝光过几个漏洞:
- 对浮点数支持更好,Protobuf 用 wire type 1(固定 64bit)来存储 double,wire type 5(固定 32bit)来存储 float,字节序都是小端,相比 JSON 能容易保证数据的一致性:
JSON 的规范并没有指明要如何处理精度,序列化框架可以自主选择自己方便的方式
当然,Protobuf 是在字节层面保证,对于浮点不能表示和不能精确表示的数,也是无能为力的
几个缺点:
不具备自解释性
不安全:
- 字符串直接拷贝
- 使用 varint 存储普通的数值类型
- 完整的编码方式参阅这里
只是读起来不太方便的二进制格式而已,还是能够算出里面的值
JSON 和 XML 等已经是某些领域通用的格式,而 Protobuf 还是很小众
兼容性是一个 trade-off,它破坏了数据的正确性,你需要在使用数据前进行一些检查
对复杂的数据类型支持不太好,比如你有一个 gRPC 服务,你想表示这样的数据:
{ "/route1": [ { "action": "GET", "params": "myparms" }, { "action": "POST", "params": "otherparms" } ], "/route2": [ { "action": "PUT", "params": "myparms" } ] }因为 Protobuf 不支持 repeated map,你想实现只能参考这个。
Tip
本周学习到的一些内容:
varint - 一种紧凑的表示数字的方法,将无意义的“0”去掉,只保留有效的数字表示位,每个字节的最高位 bit 表示下一个字节是否是本数字的一部分,如:
- 1 - 1000 0001
- 300 - 1000 0010 0010 1100
注意我用的是大端的表示
zigzag - varint 表示小数时优势很大,因为前置的“0”能最大化的去掉,但是对于负数就没有优势了,因为负数的符号位和高位都是1,没有“0”可以去掉,所以 zigzag 算法设计了几个很巧妙的规则:
- 既然符号位一定是1,那把这个符号位移到最低位,其他位整体前移一位
- 虽然符号位放到后面了,但是前导位1还是很多,于是将除符号位以外的位全部反转
- 这样就能将前置的“0”去掉了
CSDN 上的这篇文章介绍的很详情,推荐一看
varchar,多用在数据库里,高位字节表示内容长度。MySQL 用1、2个字节来存储实际的数据长度,具体用几个字节,在表结构定义时就已经确定了,所以对于同一个列,它们使用相同的字节数确定实际的数据长度:
In contrast to
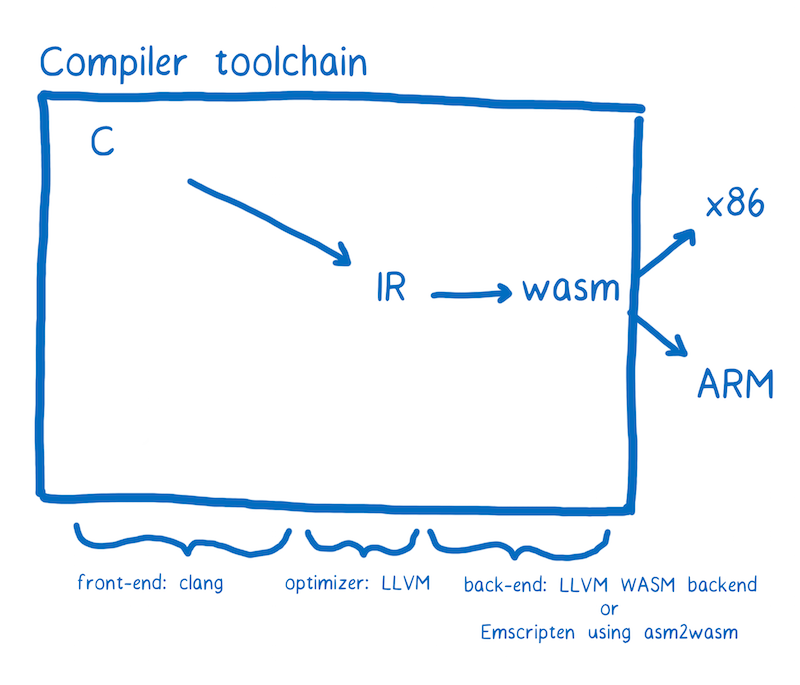
CHAR,VARCHARvalues are stored as a 1-byte or 2-byte length prefix plus data. The length prefix indicates the number of bytes in the value. A column uses one length byte if values require no more than 255 bytes, two length bytes if values may require more than 255 bytes.WebAssembly 相比 JavaScript 的优势,详情见下方的 Share
Share
本周分享:An Abridged Cartoon Introduction To WebAssembly。
虽然是17年的文章,但是对于 WebAssembly 的特点和相对于传统 JavaScript 的优势介绍的很全面,总体上会有以下几个优势:
- Downloading - 因为文件更小、更紧凑,所以能减少下载时间
- Parsing - 不需要 parsing,取而代之的是 decoding,而解码一个 WebAssembly 文件比解析一个 JavaScript 文件要快很多
- Compiling & optimizing - 只需要很少的时间做编译和优化,因为在 WebAssembly 文件上传到服务器之前就已经完成了大部分的编译和优化,而 JavaScript 在面对动态数据类型时需要编译多次
- Re-optimizing - 不需要,因为在第一次编译时就有足够的信息告诉编译器生成最好的代码
- Execution - 运行的更快,因为 WebAssembly 指令能按照机器的想法优化
- Garbage Collection - 由于不支持 GC,所以不需要花费这个时间
附上一张 .wasm 文件的示意图:
关于性能
PSPDFKit 在18年做过完整的测试:


完整版见地址:A Real-World WebAssembly Benchmark,一些后续:
- 紧接着在 18年8月 Chrome 就更新了,带来了新的编译器:Liftoff,让 PSPDFKit 的性能提高了 56%
- Edge 在 18年8月 也得到了更新,数据上已经和 Chrome 持平
- …
目前 WebAssembly 的性能已经很不错,而且后续还有很大的提升空间。
还记得 Promise 刚推出时在 Chrome 上的糟糕表现吗 :)